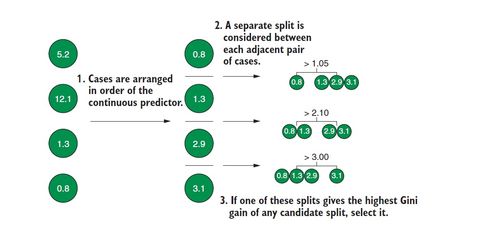
基于樹的分類算法是機(jī)器學(xué)習(xí)中的經(jīng)典方法之一,廣泛應(yīng)用于人工智能理論與算法軟件開發(fā)中。這類算法通過構(gòu)建樹形結(jié)構(gòu)對(duì)數(shù)據(jù)進(jìn)行劃分,實(shí)現(xiàn)高效的分類任務(wù)。
一、算法原理
基于樹的分類算法的核心思想是遞歸地將數(shù)據(jù)集分割成更小的子集,直到每個(gè)子集中的樣本屬于同一類別或滿足停止條件。主要包括以下步驟:
- 特征選擇:選擇最優(yōu)特征作為節(jié)點(diǎn)進(jìn)行分割,常用的指標(biāo)包括信息增益(如ID3算法)、基尼不純度(如CART算法)等。
- 節(jié)點(diǎn)分裂:根據(jù)選定的特征及其閾值將數(shù)據(jù)劃分為不同的分支,使得子節(jié)點(diǎn)的純度更高。
- 停止條件:當(dāng)節(jié)點(diǎn)中的樣本全部屬于同一類別、沒有更多特征可用,或達(dá)到預(yù)設(shè)的樹深度時(shí)停止分裂。
- 剪枝處理:為防止過擬合,對(duì)生成的樹進(jìn)行剪枝,提升模型的泛化能力。
二、常見算法
- 決策樹(Decision Tree):最基礎(chǔ)的樹模型,適用于分類和回歸任務(wù)。
- 隨機(jī)森林(Random Forest):通過集成多棵決策樹,采用Bagging和隨機(jī)特征選擇提升模型的穩(wěn)定性和準(zhǔn)確率。
- 梯度提升樹(Gradient Boosting Trees):如XGBoost、LightGBM等,通過迭代優(yōu)化損失函數(shù),逐步減少殘差,實(shí)現(xiàn)高性能分類。
三、算法實(shí)現(xiàn)
在實(shí)際軟件開發(fā)中,基于樹的分類算法可通過以下步驟實(shí)現(xiàn):
- 數(shù)據(jù)預(yù)處理:包括數(shù)據(jù)清洗、缺失值處理、特征編碼等,確保輸入數(shù)據(jù)符合算法要求。
- 模型訓(xùn)練:使用訓(xùn)練數(shù)據(jù)集構(gòu)建樹模型,通過遞歸或迭代方式生成決策規(guī)則。
- 模型評(píng)估:采用交叉驗(yàn)證、準(zhǔn)確率、精確率、召回率等指標(biāo)評(píng)估模型性能。
- 模型優(yōu)化:通過超參數(shù)調(diào)優(yōu)(如樹深度、葉子節(jié)點(diǎn)數(shù))和特征工程提升模型效果。
四、應(yīng)用場(chǎng)景
基于樹的分類算法在人工智能領(lǐng)域具有廣泛應(yīng)用,如金融風(fēng)控、醫(yī)療診斷、推薦系統(tǒng)等。其優(yōu)勢(shì)在于可解釋性強(qiáng)、易于實(shí)現(xiàn),且能處理非線性關(guān)系。
基于樹的分類算法是機(jī)器學(xué)習(xí)中不可或缺的工具,掌握其原理與實(shí)現(xiàn)方法對(duì)于開發(fā)高效、可靠的人工智能系統(tǒng)至關(guān)重要。